DBT, An Emerging Data Transformation Tool
DBT or Data build tool is a cloud based open-source tool that is slowly taking over the data world. It helps data analysts and engineers transform and manage data in their data warehouses. It is often used in conjunction with data modeling and business intelligence tools like Looker, Tableau, and Power BI.
The main purpose of dbt is to build and manage data pipelines by transforming raw data into analytics-ready data in a data warehouse. dbt does this by allowing users to define their data models in SQL and then automatically transforming raw data into these models. DBT can also automatically generate documentation for these models, making it easier for users to understand the relationships between different datasets and the transformations that were performed on the data.
DBT is designed to work with a wide range of data warehouses including Snowflake, BigQuery, Redshift, and Postgres, and is highly extensible, with a large and growing community of developers contributing to its development.
Languages used in DBT:
DBT supports the use of languages mentioned below:
1. SQL
2. Jinja
3. Python
4. YAML
DBT (Data Build Tool) primarily uses SQL for defining and building data models, transformations, and other data artifacts. It also supports Jinja, a templating language that allows for more dynamic and flexible SQL queries.
In addition to SQL and Jinja, DBT also supports Python for more advanced use cases, such as custom macros, tests, and models. Python can be used to extend DBT’s functionality and integrate with other tools or systems.
Finally, DBT also supports YAML, a markup language used for configuration files, such as defining data source connections and other project settings. YAML is used to configure and customize DBT projects, allowing users to define their data pipeline and transformations in a structured and repeatable way.
Distinguishing features of DBT:
There are numerous applications for DBT. The following are some typical use cases:
Use Cases:
DBT is a versatile tool that can be used in a variety of use cases, including:
Data Warehousing: DBT enables you to build, manage, and maintain data pipelines that transform data in a cloud data warehouse. With dbt, you can extract data from multiple sources, transform it, and load it into your data warehouse.
Analytics: DBT enables you to build analytics-ready data pipelines that can be used to build dashboards, reports, and visualizations. With dbt, you can transform data in a way that makes it easy to analyze and visualize.
Machine Learning: DBT can be used to prepare and transform data for machine learning models. With dbt, you can join, filter, and transform data in a way that makes it suitable for machine learning.
DBT On Premises and DBT Cloud:
DBT can be used on cloud using the IDE integrated on their website. You can use this link: https://cloud.getdbt.com/
You need to sign up and then you can start using it. You have to tell it the target and source database. dbt makes all the basic files needed for the starting the project. You can click on the develop tab and see the IDE as shown below:
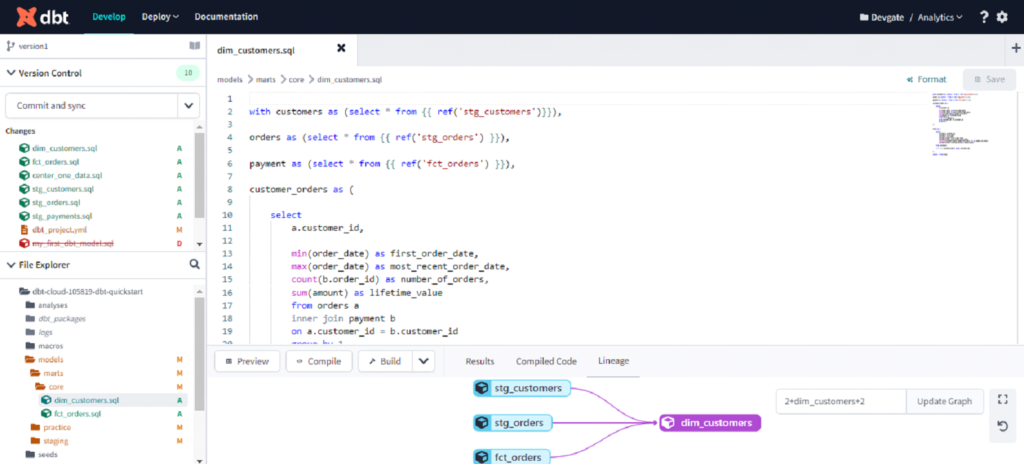
The other way to use dbt is on premises. You can make a clone of the GitHub repository containing all dbt files in your local machine. Then you can run it on any of your favorite IDE, after integrating it with DBT. DBT on premises is much faster in running the query but it does not have the feature of previewing the model as dbt cloud does. Another distinguishing feature of dbt cloud is that it creates lineage of all the sources being used in creation of a table.
How to Use DBT:
Inside the files that DBT creates automatically, you can find the models folder. Inside this folder you can create your SQL scripts. You can set the name of the file exactly as the table that needs to be created in your target database. You have to write the ‘select’ query in this file and save it. dbt will automatically create the table in target database after you run that model using ‘dbt run’ command.
Pros and Cons of DBT:
Pros:
Ease of Use: DBT is easy to learn and use, especially if you are already familiar with SQL. It simplifies the development of data pipelines by enabling data teams to write modular, scalable, and well-documented SQL code.
Modular Design: DBT’s modular design makes it easy to build and maintain pipelines over time. You can break down complex pipelines into smaller, reusable components, which makes it easier to manage and maintain the codebase.
Version Control: DBT’s integration with Git enables teams to collaborate effectively and maintain high-quality code over time. With Git, you can track changes, review code, and roll back changes if necessary.
Flexibility: DBT is a versatile tool that can be used in a variety of use cases, including data warehousing, analytics, and machine learning. It allows you to transform data in a way that makes it easy to analyze and visualize.
Open-Source: DBT is an open-source tool that is free to use and can be customized to fit specific use cases. The community around dbt is active and provides support, making it easy to get help when you need it.
Cons:
SQL-Based: DBT’s SQL-based approach may not be suitable for users who prefer to use other programming languages. While dbt supports Python, users who prefer to use other languages may find dbt less appealing.
Limited Functionality: DBT’s primary focus is on data transformation, which means that it may not be suitable for users who require more advanced ETL functionality. Users who require more advanced functionality may need to use additional tools in conjunction with dbt.
Learning Curve: While DBT is relatively easy to use, there is still a learning curve involved. Users who are new to SQL or data pipelines may need some time to get up to speed with dbt.
Cloud Dependency: While DBT can be used locally, it is designed to work in the cloud. This means that users who prefer to work locally may find dbt less appealing.
Lack of Native Visualization: DBT does not provide native visualization capabilities, which means that users need to use additional tools to create dashboards and visualizations based on their data.